| Phase |
Objective |
Key Actions |
Tech / Patterns |
Team Roles |
Timeline |
Success Metrics |
Risks |
Mitigation |
Output Deliverables |
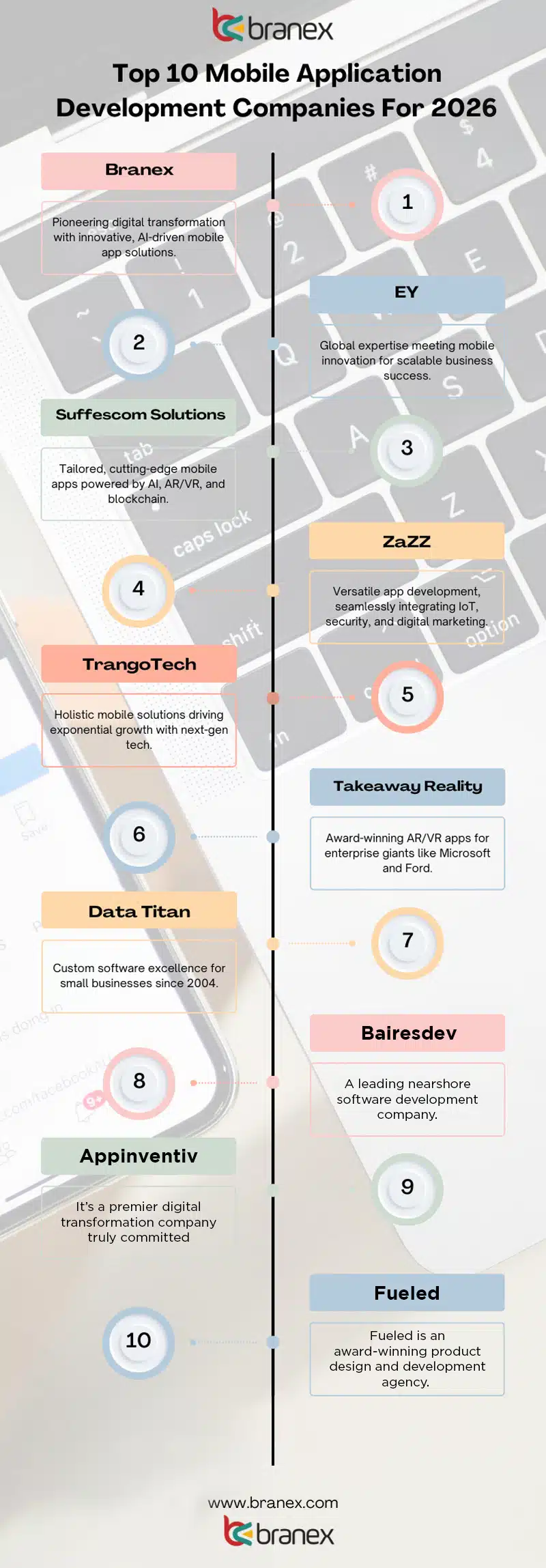
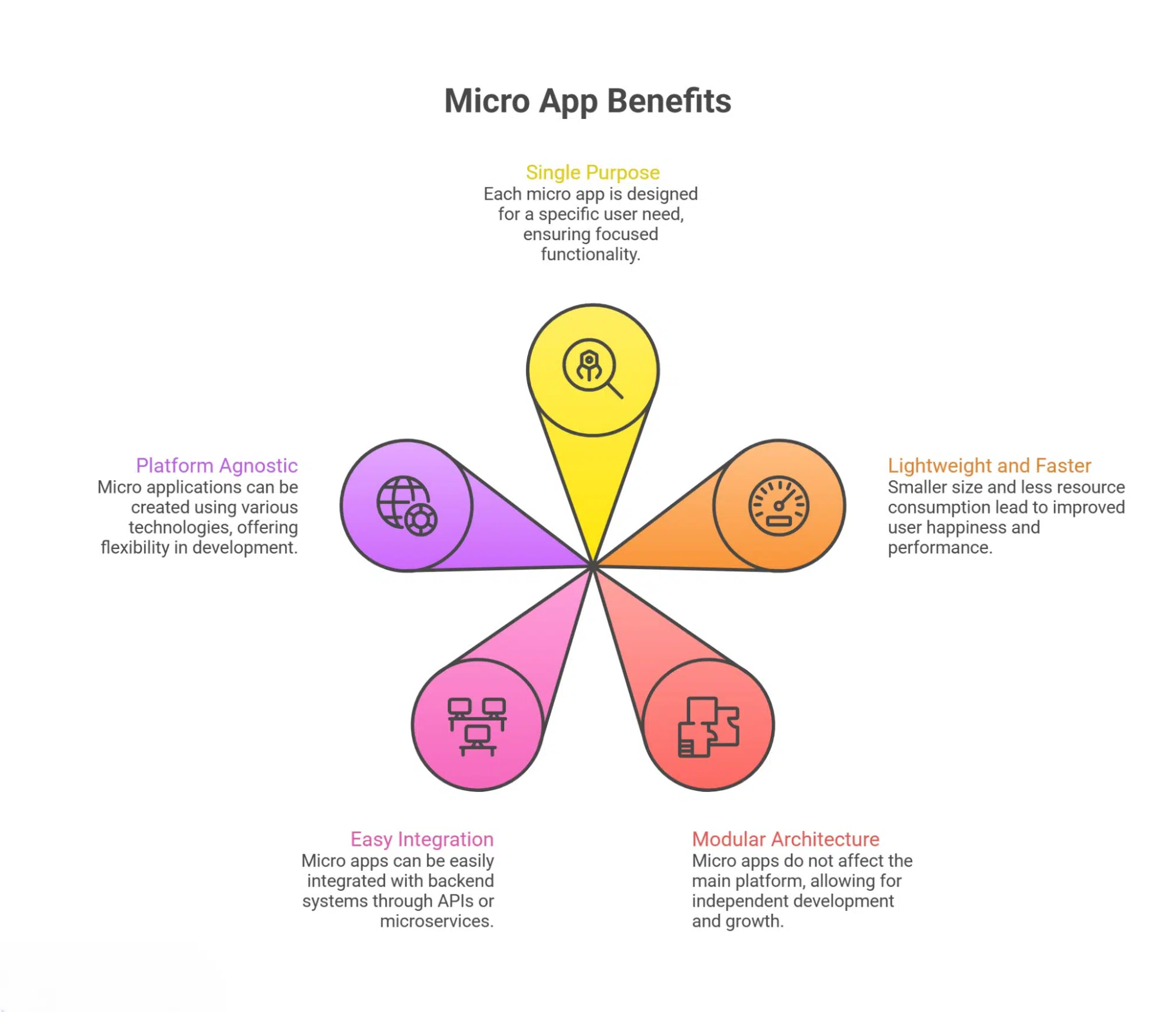
| 1. Core Use Case & Distribution |
Establish high-frequency anchor + initial traction |
Market analysis, MVP build, retention testing, GTM strategy, partnerships |
MVP stack, analytics tools |
PM, UX Researcher, Mobile Eng, Data Analyst, Marketing Lead |
4–12 weeks |
DAU/MAU traction, D1/D7/D30 retention, 10k+ users |
Wrong core, low adoption |
Rapid iteration, feature flags, bundling partnerships |
MVP, analytics setup, GTM plan, compliance checks |
| 2. API Gateway (Platform Foundation) |
Centralize service orchestration and control layer |
Gateway setup, auth (OAuth2/JWT), versioning, contract testing, rate limiting |
API Gateway (Kong, AWS, Spring), BFF pattern, OpenAPI |
Solution Architect, API Dev, Security Eng, QA |
4–6 weeks + ongoing |
100% traffic via gateway, zero breaking changes, stable uptime |
SPOF, breaking APIs |
Redundancy, contract testing, staged rollouts |
Gateway infra, API docs, CI contract tests |
| 3. Micro-Frontends (MFE Layer) |
Enable independent UI deployment and scale velocity |
Shell app, module federation, state isolation, CI/CD per MFE |
Webpack Module Federation, Single-SPA (optional), Event Bus |
Frontend Eng, DevOps |
6–12 weeks + sprint cycles |
Independent deploys, <1s load time, zero merge conflicts |
Bundle bloat, performance issues |
Shared deps, lazy loading, caching |
Shell app, MFE pipelines, design system |
| 4. Modular Backend + Data Ownership |
Build scalable, decoupled services |
DDD, service isolation, DB per service, Saga pattern, event streaming |
Microservices, Kafka, CQRS, Saga orchestration |
Backend Eng, Data Eng, DevOps |
8–12 weeks + iterative |
Independent scaling, zero shared DB, high test coverage |
Data duplication, skill gaps |
Event-driven design, architecture governance |
Service repos, DB schemas, event pipelines |
| 5. Partner Ecosystem (Platform Expansion) |
Turn product into platform via third-party integrations |
SDKs, developer portal, sandbox env, onboarding workflows |
Mini-app architecture, API SDKs, CDN hosting |
Platform Eng, DevRel, Partnerships |
4–6 weeks + 3–6 months scale |
<4 week onboarding, partner retention, ecosystem growth |
Poor DX, integration friction |
Zero-touch onboarding, strong docs |
Dev portal, SDK, sandbox, onboarding flows |
| 6. Embedded Finance & Compliance |
Monetization + regulatory readiness |
Payments, KYC/AML, PSP integration, risk scoring, compliance frameworks |
PCI-DSS, KYC APIs, encryption, zero-trust security |
Fintech Eng, Compliance Officer, Security Eng |
3–6 months |
<1% payment failure, audit pass, fraud detection accuracy |
Regulatory delays, data breaches |
Early regulator alignment, encryption, modular compliance |
Payment infra, KYC flows, audit systems |
| 7. Observability & Reliability (SLOs) |
Ensure system resilience and uptime |
Logging, metrics, tracing, SLO definition, alerting, chaos testing |
Prometheus, Grafana, ELK, OpenTelemetry |
SRE, DevOps |
4–6 weeks + ongoing |
99.9% uptime, incident detection speed, SLO compliance |
Alert fatigue, blind spots |
SLO-based alerts, centralized monitoring |
Dashboards, runbooks, incident workflows |
| 8. Infrastructure & CI/CD |
Enable scalable, repeatable deployments |
CI/CD pipelines, containerization, IaC, release strategies |
Kubernetes, Terraform, GitOps, Serverless (selective) |
DevOps, Cloud Architect |
4–6 weeks + 3–6 months scale |
Fast deployments, rollback capability, zero downtime releases |
Deployment failures, infra complexity |
Canary releases, blue-green deploys |
CI/CD pipelines, K8s clusters, IaC repos |
| 9. Growth Metrics & Economics |
Ensure sustainable scaling via data |
LTV/CAC modeling, cohort analysis, A/B testing, dashboards |
Analytics stack, BI tools, experimentation frameworks |
Data Analyst, Growth Marketer, PM |
Ongoing (initial 6–8 weeks setup) |
LTV:CAC ≥ 3:1, retention growth, CAC payback <12 months |
High CAC, churn |
Optimize funnels, shift to organic growth loops |
Analytics dashboards, KPI reports |
| 10. Team Structure & Governance |
Maintain velocity without chaos |
Cross-functional squads, platform team, governance frameworks, DevEx tooling |
Agile (Scrum/Kanban), internal SDKs, dev portals |
CTO, Eng Manager, Squad Leads |
Ongoing |
High deployment frequency, low coordination overhead |
Team silos, governance friction |
Guilds, shared standards, DevEx investment |
Team model, dev portal, standards documentation |







 Team Branex
Team Branex












 Anticipatory design will emerge as a UX strategy where it will use data to predict what a user desires before they even inquire. The goal of an anticipatory design is to achieve a zero UI state where the user doesn’t have to go to a different menu at all because the system will already perform the task for him/her. It will reduce cognitive overload and make the technology much more safer and helpful for the users.
Anticipatory design will emerge as a UX strategy where it will use data to predict what a user desires before they even inquire. The goal of an anticipatory design is to achieve a zero UI state where the user doesn’t have to go to a different menu at all because the system will already perform the task for him/her. It will reduce cognitive overload and make the technology much more safer and helpful for the users. 




 Framework: Native (Swift / Kotlin)
Framework: Native (Swift / Kotlin)
 Framework: Flutter
Framework: Flutter
 Framework: React Native
Framework: React Native
 Framework: Kotlin Multiplatform (KMP)
Framework: Kotlin Multiplatform (KMP)
 Framework: .NET MAUI
Framework: .NET MAUI
 Framework: Ionic
Framework: Ionic

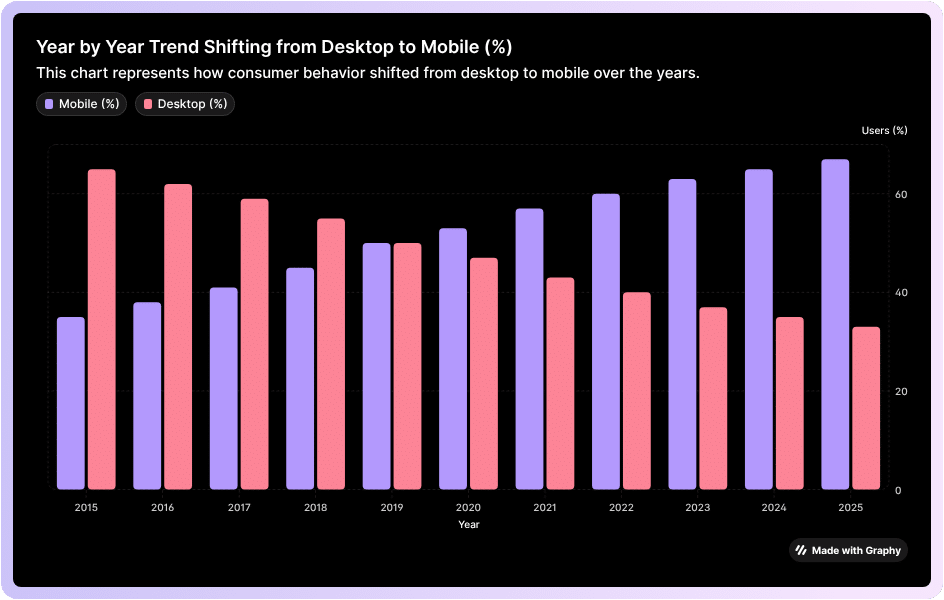


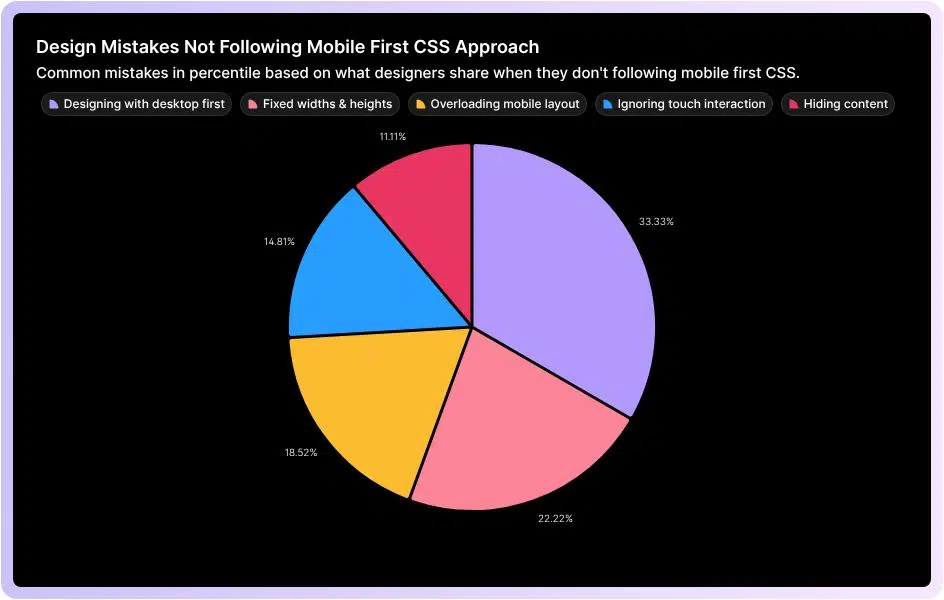

 Start with the smallest screen first mindset:
Start with the smallest screen first mindset:
